
Hello, this is
Xiaohan Zou (邹笑寒).
I do machine learning by day and build things for the web by night.
Bio
I am a Ph.D. student in the Computer Science and Engineering Department at Pennsylvania State University advised by Prof. Huijuan Xu. My current research interests primarily focus on understanding and enhancing the generalizability, efficiency, robustness, and other crucial aspects of machine learning. I am also interested in large multimodal models.
Previously, I received my master’s degree in Computer Science from Boston University and my bachelor’s degree in Software Engineering from Tongji University. I also interned at Kuaishou and PKU.
By the way, take a look at some things I’ve built as a web developer, featuring ohmycv.app - a sleek, privacy-first online resume builder.
Education
| Ph.D. in Computer Science and Engineering, Pennsylvania State University | 2023 |
| M.S. in Computer Science, Boston University | 2021-2023 |
| B.Eng. in Software Engineering, Tongji University Thesis: Food Image Aesthetic Assessment and Captioning | 2016-2020 |
Publications (also see Google Scholar)
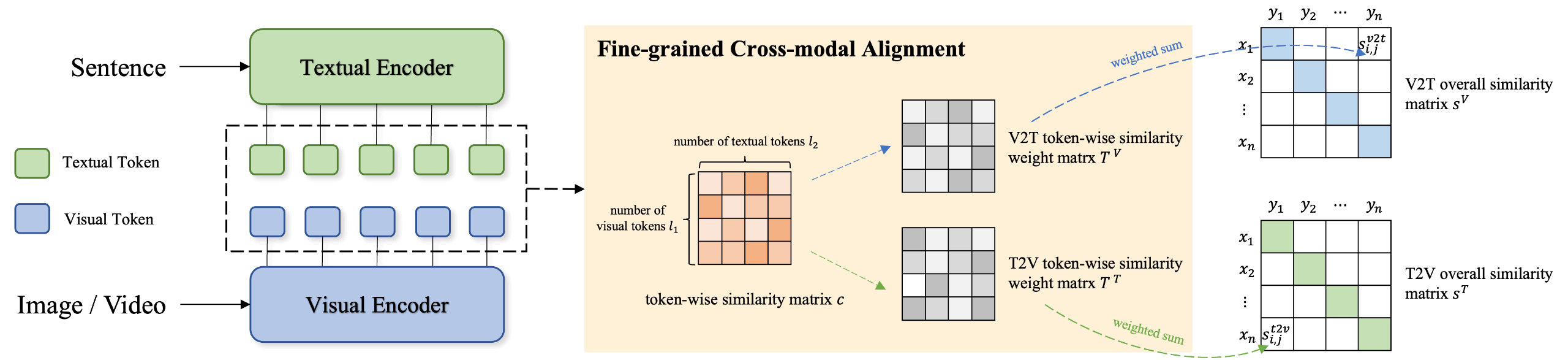
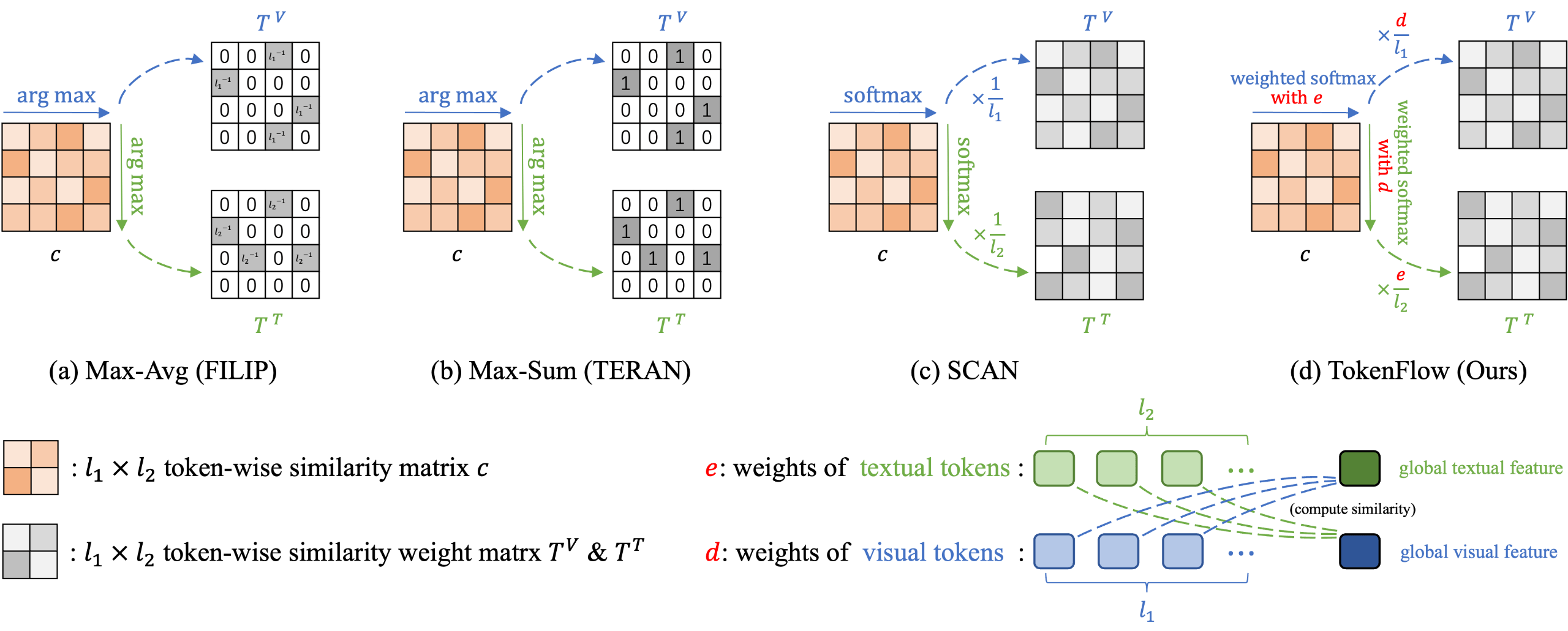
TokenFlow: Rethinking Fine-grained Cross-modal Alignment in Vision-Language Retrieval
Xiaohan Zou, Changqiao Wu, Lele Cheng, and Zhongyuan Wang
Preprint, 2022
A Survey on Application of Knowledge Graph
Xiaohan Zou
International Conference on Control Engineering and Artificial Intelligence (CCEAI), 2020
Talks
- Meta / Few-shot Learning, Kuaishou, 08/2021
- Continual Learning: Meta Continual Learning & Task Free Settings, Peking University, 08/2020
Miscellaneous
-
🚀 This personal website is built with Astro, Solid and UnoCSS
-
🧐 Renovamen is a Latin word means renewal
-
🖥 Ex-OIer/ACMer
-
🥎 Used to be a member of the softball team of Tongji University
-
🌭 My dream:
while(sleeping){money++;} -
🕹️ Currently interested in Minecraft and Monster Hunter: World
-
📜 大概率更新不及时的中文简历